
Autonomous agents are coming
My experience with an autonomous agent and when to use them

Autonomous agents are the latest trend in AI. To give you some sense of how fast this space is evolving, check out the graph below for Auto-GPT (one of the open-source autonomous agent projects). Developers “star” a project when they want to keep up with it. Github stars are an excellent way to measure to the traction of a particular project.

In this essay, I’m going to give you a step-by-step walk through of what autonomous agents are. We’ll use an open-source autonomous agent to run through a real example. In addition, I want to share my thoughts on the kind of problems agents are best placed to tackle.
What is an autonomous agent?
An autonomous agent takes a goal and completes it for you.
The magic of an autonomous agent is that it does everything required to complete that goal. It is able to figure out the tasks required to complete the goal, plan them, prioritise them and complete each one. It is able to think sequentially, update itself with new information and even correct itself when it spots mistake.
Autonomous agents are new and prone to errors. But don’t let this hold you back too much. Remember that ChatGPT was released in November 2022 and GPT4 a few weeks ago. We are very early. The fact that this is possible already is mind blowing.
Walking through an example
One of the most popular autonomous agents was developed by Yohei Nakajima. It’s called BabyAGI. Yohei chose the name because of early signs of artificial general intelligence (AGI). A precise definition of AGI is hard to find. Think of it as a machine that can do anything. Yohei was half joking when he chose the name, but you will quickly see why the name is very relevant.
I’m going to use BabyAGI to demonstrate how an autonomous agent completes a goal. It’s a very elegant, simple implementation that will allow us to understand how agents actually work.
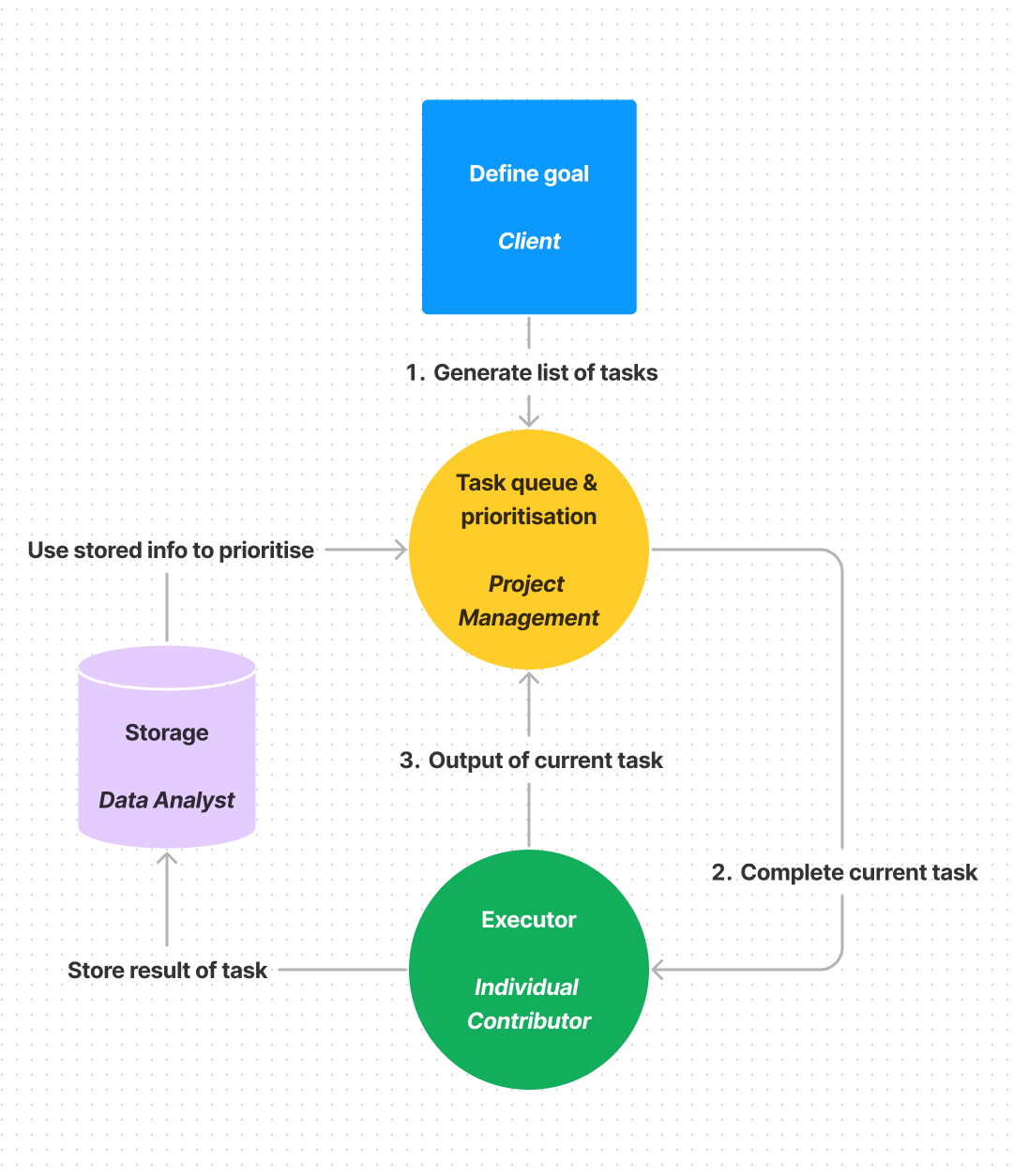
Before jumping into the details, here’s a quick framework to think through what’s happening under the hood. For the sake of simplicity, consider a company that takes on projects on behalf of a client. The company has project managers, individual contributors and a data analyst.
User input: a client comes to the company with a specific goal.
Task queue and prioritisation: the project management team considers the requests and lists out all the tasks required to complete the request. It orders tasks to account for dependencies between them.
Executor: The project management team then issues the first task to an individual contributor and asks them to complete it. When the task is done, the individual contributor lets the project management office know, and submits the results to the data analyst.
Storage: All output from tasks is stored by the data analyst in a database somewhere.
This process is recursive. Every time a task a completed, the project management office reconsiders the lists of tasks and prioritises them. To ensure it has the latest information, it reaches out to the data analyst to learn about the output from all previous tasks.
Now that we have a framework in place, let’s jump in.
The goal [User input]
One of the main use cases of my product, Kili, is helping customer support teams reduce resolution time. Naturally, I might want to do some market research and map out the competitors in the space.
With this in mind, I’m going to provide the following goal:
Find all companies building AI-enabled customer support products
Generate an initial list of tasks [Task queue & prioritisation]
When you provide a goal, the agent uses AI (i.e. ChatGPT) to create a list of tasks to complete the goal.
For my specific goal, the agent came up with the following initial tasks:

Complete the first task [Executor]
Once it has the list of tasks, it takes the first task and executes it. For this specific goal, the agent completes the task using the equivalent of ChatGPT. A more advanced assistant could search the web to complete the task or use a different tool.
The agent completes the task by finding a list of companies. It also thinks about what to do next — in this case, find the list of products offered by each of those companies.

After every task is completed, the output is saved in “storage” (the data analyst). In addition, the output is passed on to the task queue and prioritisation function (the project management team).
Re-prioritisation [Task queue and reprioritisation]
When the project management team is notified that a task has been completed, it does two things:
Figures out if it needs to add any other tasks to achieve the goal
Re-prioritise the list of tasks to do them in the most efficient order
In our case, it decides that the next best task is to analyse the reviews of ratings of the companies identified above.

This happens in a loop until the agent believes that the goal has been achieved. Here’s a list of tasks that were completed as part of this goal:
Identify the AI-enabled customer support products offered by each company on the list.
Analyze customer reviews and ratings of the AI-enabled customer support products offered by the following companies on the list: Zendesk, Freshdesk, Help Scout, Intercom, Zoho Desk, Kayako, HappyFox, Groove, Desk.
Research the features and functionalities of AI-enabled customer support products offered by Ada Support.
Determine the market share of each company on the list in the AI-enabled customer support industry.
Identify any partnerships or collaborations between the companies on the list.
Identify any unique features and functionalities of the AI-enabled customer support products offered by the companies on the list.
What do we think?
Overall, I cannot look at the output of this program and use it without review. Irrespective, it feels magical that this is possible. This will get better, and get better really fast.
The agent didn’t do well with tasks like determining market shares or identifying pricing. These can easily be solved by giving the agent the ability to access the internet.
The agent also goes off on a tangent. For example, in the example above, the agent compiled the list of customer service software companies several times even though it had completed the task before. Some of these problems will be solved by simply tuning up the code. Others can be solved by a human guiding the agent after a few intermediary steps.
Even if many of the tasks were not completed, the agent still produces information that was useful:
A list of competitors in the domain
A summary of where each competitor does well (via reviews)
Information on what segments each competitor focusses on (not shown but the agent did it for me)
I estimate this saving me at least an hour. It cost me a few cents at best to run and I could do other, more impactful stuff (like writing this essay) while it was running. This is going to improve productivity for everyone massively.
So here’s a more relevant question: what problems should autonomous agents tackle?
Where to apply autonomous agents?
Autonomous agents are best suited to problems that meet the following criteria:
Open-ended tasks
If you’re going to use an agent, you should do so for an open-ended task.
An open-ended task is something that requires multiple steps and thinking through each step before proceeding to the next. If the task is basic, and you believe there is a single, well-defined route to get there, don’t use an agent. Instead, automate the task entirely using whatever tool you can. It’s going to be more productive, efficient and a better user experience.
Individual tasks
Intuitively, it feels better to start with tasks that need to completed by 1 person.
If multiple people need to coordinate to get something done, there’s an added layer of complexity. Instead, it might be worth choosing a sub-task (i.e. something that needs to be done by a single member of the team) and letting an autonomous agent solve it.
Error threshold
Autonomous agents should take on tasks where the consequence of an error is not very high.
This framing holds true for LLMs in general but applies more to agents. Agents are essentially recursively using an LLM. Assuming your accuracy rate with an LLM is 80%, after 5 iterations your accuracy goes down to 80% ^ 5 = 33%.
Human in the loop
Accuracy with agents will improve over time. Until it does, it’s best to find problems where an agent can be deployed with a human in the loop.
If someone can check the agents work at different checkpoints, accuracy could improve dramatically. Even with a human in the loop, the productivity gains from an agent could be massive.
To close
Autonomous agents are exciting. They are LLMs on a loop that guide themselves through tasks to achieve an overarching goal. It’s easiest to think of it as a team within an organisation who is taking on a project.
If you’re interested in digging deeper, I recommend the following Github repos: