


Choosing your AI model
How do you choose the right LLM?

Large language models (LLMs) are all the buzz right now. You’ve probably heard of GPT3.5, which ChatGPT is based on, and there’s new one almost every week. Xavier Amatriain published an excellent paper with a catalogue of LLMs from which I’ve lifted the graphic below.

Every time I read a paper on a new LLM, my brain hurts a little. It takes me a while to process what the innovation of the model was and whether it was superior to predecessors. Separately, I’ve struggled to find a resource that provides a framework for how to choose the right LLM for your use case.
So this week, I decided to put these two together and write an essay on it. To set expectations, you will not leave knowing exactly what model to use. But I do hope that you will leave with a set of questions you should try and answer before choosing the right model for your use case.
A primer on LLMs
Large language models (LLMs) are AI algorithms designed to produce human-like responses and dialogue. A complete history of LLMs or how they work technically is beyond the scope of this essay. Instead, I’ll leave you with a little bit of history and some context on how LLMs are evaluated.
A brief history
In 2017, a bunch of AI researchers published a paper called “Attention is all you need”. The paper introduced Transformers, a novel way to translate text from English to German. This paper forms the basis for many of the LLMs in use today — the authors seriously underestimated the impact of their work!
LLMs are designed to take in a piece of input and respond to it like a human would. Imagine some asks: “Which country is Paris in?”. Prior to transformers, the algorithm would process each letter at a time. This was time consuming and computationally intensive. Transformers changed this by allowing the entire sentence to be absorbed in one go.
People often refer to this as “Attention”. This is because Transformers have the ability to focus on a specific part of the text. In the example above, the Transformer is able to recognise that “Paris” is a key part of the input sentence.
Understanding LLM announcements
Given the pace of AI development, it wouldn’t be extreme to expect 1 announcement on LLMs each week for the rest of the year. Just this week, Meta announced a new LLM:





Every LLM announcement includes a few standard call outs which I describe below.
Parameters
To understand parameters, think of a simple equation like the one below:
To predict a value “y”, we need to estimate β0 and β1. Given these estimates and input values (0 and x) you can predict “y”. Whilst LLMs are much more complex, the overarching principle is the same: they are predicting a set of parameters β0, β1, β2, ..., βp. Then, when you ask a question like “Which country is Paris in?”, the LLM applies the input to its model and generates some output. When an LLM claims to have more parameters, it means the “equation” is more complex.
Training tokens
The second feature of every LLM announcement is the amount of data the model was trained on. This is usually measured using “training tokens”. Tokens are a measure of the quantum of text. Tokens are used instead of raw character counts for a variety of reasons: researchers clean text before using it in their model, not every character carries the same weight etc. The main takeaway here is that the number of training tokens tells you the quantum of data the model was trained on.
Parameter vs. training tokens
To date, model improvement has largely focussed on increasing the number of parameters. For example, GPT-3 was trained on 175 billion parameters. It’s predecessor, GPT-2, was trained on 1.5 billion parameters.
It’s unclear if increasing parameter size alone will continue to give us the improvements we’ve seen to date. One of the most important papers in 2022 (Hoffman et all, 2022) found that the number of parameters and the amount of training data should be increased in the same proportion.
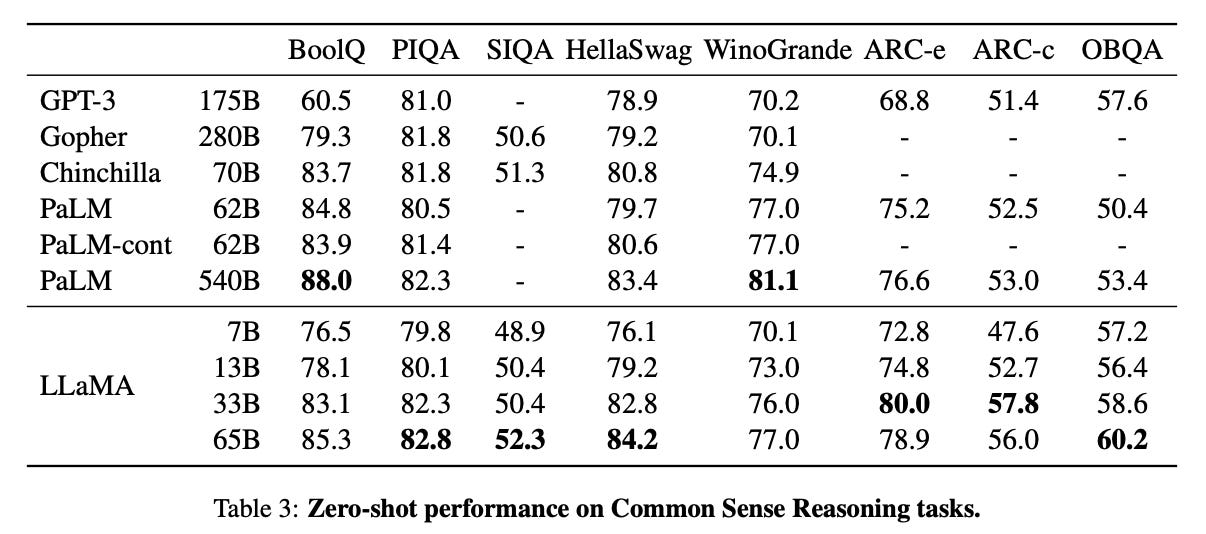
Evaluation criteria
In addition to the above, you will also find evaluation criteria mentioned on every AI announcement. For example, the table has each LLM as a row, and evaluation criteria as a column. Think of these criteria as a text or exam for the LLM to perform. the OBQA (open book question answer) is data set of question and answers. The table shows that LLaMA’s 65 billion parameter model achieved a 60% score on the exam beating every other model in the table.
Other features
There’s a bunch of other stuff in announcements that is worth taking into account. Most models will detail the technical architecture used for the model. They will also call out the training data used to train the model.
Now that we have some framework to evaluate LLMs, let’s look at how we might choose the one we want to work with.
What is your use case?
Before getting into LLMs,I think it’s useful to ask fundamental questions about your use case:
Response times: How fast do your users need a response?
Budget: How much are you willing to spend to answer each question?
Accuracy: What is your threshold for accuracy?
Privacy: Is privacy a concern?
Product maturity: What stage of development are you at?
Here’s a little framework for thinking about these questions:
The LLM trifecta
It’s best to think about response times, budget and accuracy together.
Generally speaking, the more expensive models take longer and are more accurate. If you want something that is really quick, you will need a model that is simpler. For example, Da Vinci is the most advanced model offered by OpenAI. When I was testing it, it took 4 - 6 seconds to answer each question. If you switch to Curie, the response times are 1 - 2 seconds. I haven’t really found a resource that documents the response times of all LLMs. Generally speaking, the more complex the LLM the more expensive it is and the longer it takes to get a response.
Privacy
Ask yourself if privacy is important for your use case.
Do you need to handle personally identifiable information like an email address or phone number? If so, you probably don’t want to send it to an LLM hosted by someone else. Even if you do, the customers you service may not want to. If this is the case, at a minimum, you want to explore open source LLMs like Google’s Flan. And if you are doing so, make sure you check the licenses of these LLMs.
Product maturity
Be clear about how mature your product is.
If you are early stage, chances are you will need to do a lot of tinkering. You really do not want to be training models from scratch at this stage unless you really have to. It’s a waste of time and money. It’s far better to use an off the shelf model, even if it means you pay more, and then move away once you are really clear on your use case.
Vertical
If you are building in a very specific vertical, consider a context specific LLM.
Depending on your vertical, you might find that an LLM trained on text specific to your domain works better. BioGPT, an LLM trained specifically on biomedical texts was found to outperform previous models on most tasks.
To close
Choosing the right LLM is hard. It’s even harder when there is a new one coming out each day.
There’s no magic answer to this question. The best you can do is to keep yourself up to date with LLM announcements. Start reading AI papers. Unless you’ve been in AI and ML for a while, it will be a struggle. Push through and focus on a few key questions: what was this model trained on? How large is the model? How and what data was it trained on? How was it evaluated?
Next, ask yourself what’s really critical for your use case. Is it latency, accuracy, privacy or all of these? Once you have these answers, pick 3-5 models you want to test. If you are early stage, I recommend using off the shelf APIs and trying different models. This space is SO early that nothing beats putting a prototype in front of a user and seeing how they do.